Apache Kafka(아파치카프카) is an information collection, handling, storage space, and assimilation system that accumulates, processes, shops, and integrates information at range. Information combination, dispersed logging, and stream handling are simply a few of the many applications it may be used for. To totally comprehend Kafka’s actions, we should first recognize an “occasion streaming system.” Prior to we discuss Kafka’s architecture or its main parts, let’s talk about what an occasion is. This will certainly assist in explaining how Kafka conserves occasions, exactly how events are gotten in as well as exited from the system, in addition to how to evaluate occasion streams once they have actually been kept.
Kafka shops all received information to disc. After that, Kafka copies data in a Kafka collection to maintain it safe from being lost. A lot of points can make Kafka sprint. It doesn’t have a great deal of bells and whistles, so that’s the first thing you should understand about it. One more reason is the absence of unique message identifiers in Apache Kafka. It takes into account the time when the message was sent out. Additionally, it does not monitor that has actually read about a specific subject or who has actually seen a particular message. Customers should monitor this information. When you obtain information, you can just select a balanced out. The data will after that be returned in turn, starting with that said countered.
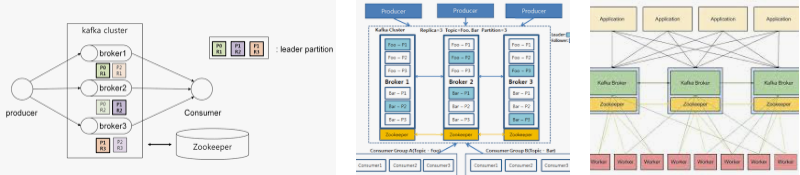
Apache Kafka Style ㅡ 아파치카프카 사용법
Kafka is commonly made use of with Tornado, HBase, as well as Spark to deal with real-time streaming information. It can send a lot of messages to the Hadoop collection, no matter what industry or use case it is in. Taking a close look at its atmosphere can assist us much better understand just how it works.
- Create and subscribe to streams of records
- Effectively save streams of records in the order that records were created.
- Process records into streams in real-time
Apache kafka is used primarily to create real-time streaming data pipelines as well as applications that can adapt to a stream of data. It blends storage, messaging and stream processing to enable the storage and analysis of real-time and historical data.
APIs
It includes 4 major APIs:
– Producer API:
This API permits apps to transmit a stream of data to several topics.
– Customer API:
Using the Customer API, applications may subscribe to one or perhaps a lot more subjects and also take care of the stream of data that is generated by the subscriptions
– Streams API:
One or more topics can use this API to obtain input as well as result. It transforms the input streams to outcome streams so that they match.
– Connector API:
There are reusable producers in addition to consumers that may be connected to existing applications thanks to this API.
Parts and Description
– Broker.
To keep the load balanced, Kafka collections normally have a lot of brokers. Kafka brokers utilize zooKeeper to monitor the state of their clusters. There are hundreds of hundreds of messages that can be reviewed as well as contacted each Apache Kafka broker concurrently. Each broker can handle TB of messages without decreasing. ZooKeeper can be made use of to elect the leader of a Kafka broker.
– ZooKeeper.
ZooKeeper is utilized to keep an eye on and coordinate Kafka brokers. The majority of the time, the ZooKeeper solution informs manufacturers and also customers when there is a brand-new broker inside the Kafka system or when the broker in the Kafka system doesn’t work. In this situation, the Zookeeper obtains a record from the producer and the consumer concerning whether the broker is there or not. Then, the manufacturer and the consumer decide as well as begin collaborating with another broker.
– Producers.
People who make points send information to the brokers. A message is immediately sent out to the new broker when all manufacturers first introduce it. The Apache Kafka producer does not await broker acknowledgements and transfers messages as quickly as the broker can handle.
– Customers.
Since Kafka brokers remain stateless, the consumer must keep an eye on the number of messages eaten via dividers countered. If the consumer says that they’ve read every one of the previous messages, they’ve done so. The consumer demands a buffer of bytes from the broker in an asynchronous pull demand. Individuals might return or onward in time inside a partition by giving an offset value. The value of the customer balanced out is sent to ZooKeeper.
Conclusion
That ends the Introduction. Bear in mind that Apache Kafka is without a doubt an enterprise-level message streaming, posting, and also consuming system that may be utilized to link various autonomous systems.
Reference : 아파치카프카 사용법 by nacsociety